
Introduction
Cloud budgets have never been larger — and neither has the waste inside them. Synergy Research reports trailing twelve-month cloud infrastructure revenues hit $390 billion as of Q3 2025, yet Flexera's 2026 State of the Cloud Report estimates that 29% of IaaS/PaaS spend is simply wasted — after five years of gradual improvement, that number is climbing again.
Block storage is where a lot of that waste hides. Unlike idle compute instances that trigger cost alerts quickly, storage volumes persist and bill silently long after the workloads that needed them are gone. Engineers know shrinking storage is painful — so they don't. The bills accumulate quietly.
What follows covers the scale of cloud storage waste in 2026, why it keeps growing despite better tooling, and the specific categories — and fixes — that matter most.
Key Takeaways
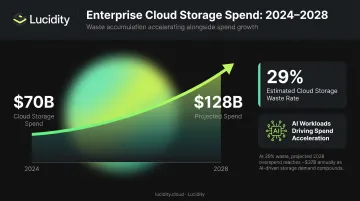
- Flexera estimates 29% of cloud budgets are wasted on average in 2026; storage-specific waste is chronically undercounted in that figure
- Enterprise cloud storage spend is projected to reach $128 billion by 2028, with over-provisioning and idle volumes representing a substantial share of that total
- Cloud efficiency rates have fallen from 80% to 65% in one year, partly driven by ungoverned AI storage provisioning
- Four waste categories drive most losses: unattached volumes, over-provisioned disks, orphaned snapshots, and zero-I/O volumes — each needs a distinct fix
- Autonomous storage optimization can increase disk utilization from roughly 30% to 75% and cut block storage costs by up to 70%
The Scale of Cloud Storage Waste in 2026
The Waste Numbers Are Getting Worse, Not Better
After five consecutive years of decline, estimated cloud waste reversed direction. Flexera's 2026 data puts wasted IaaS/PaaS spend at 29% — a figure made more alarming by how much faster cloud spending is growing. With Synergy Research tracking $390 billion in trailing annual cloud infrastructure revenues, even a conservative waste rate translates to tens of billions of dollars burned annually.
Storage is a meaningful but poorly tracked slice of that waste. Enterprise cloud storage spending hit nearly $70 billion in 2024 and is projected to double to $128 billion by 2028, driven largely by AI adoption and expanding data demands. As that market grows without proportional governance, idle and over-provisioned storage volumes accumulate — mostly untracked, consistently billed.
Utilization Tells the Real Story
Lucidity's platform has analyzed over 100 petabytes of storage capacity across 600+ enterprise assessments. The consistent finding: the average enterprise runs at approximately 30% disk utilization. That means roughly 70% of provisioned block storage capacity is sitting unused at any given time — paid for, generating no value.
That gap between provisioned and actual usage is the definition of storage waste — and it's the default state for most enterprise cloud environments, not an exception.
Key patterns Lucidity consistently sees across assessments:
- ~70% of provisioned block storage sits idle at any given time
- Unattached, unmounted, and zero-I/O disks are the primary waste categories
- Over-provisioning persists because resizing storage is complex and carries performance risk
AI Is Accelerating the Problem
That utilization gap is widening — and AI workloads are the primary reason. CloudZero's FinOps in the AI Era report found that the median Cloud Efficiency Rate dropped from 80% to 65% in a single year — erasing years of disciplined spend optimization in one reporting cycle.
The driver: AI workloads. Training datasets, model checkpoints, embedding stores, and inference logs are provisioned generously and rarely cleaned up. The FinOps Foundation's guidance on AI workloads explicitly flags this accumulation pattern and recommends matching storage to access patterns with enforced lifecycle policies — yet most organizations still have no automated mechanism to enforce them. Without one, each new AI project adds another layer of unreclaimed storage spend.
Root Causes: Why Cloud Storage Waste Persists
The Expand-Easy, Shrink-Hard Problem
Cloud providers made storage provisioning easy by design. Shrinking it is a different story entirely:
- AWS EBS: You cannot decrease EBS volume size. Full stop.
- Azure Managed Disks: Direct downsizing is unsupported. The workaround requires creating a smaller disk, copying data, and deleting the original — a manual, error-prone process with data loss risk.
- Google Persistent Disk: You cannot reduce disk size. A smaller disk means replacing the existing one entirely.

This asymmetry makes over-provisioning the rational default. Engineers allocate generously upfront because rightsizing later is genuinely hard — and the tools don't make it easier.
Visibility Gaps and Misaligned Incentives
Two organizational dynamics compound the technical constraints:
- No volume-level visibility. An Anodot survey found that 54% of organizations cite lack of visibility into cloud usage as their primary source of waste, and 50% flag complex pricing models. Native cloud dashboards aggregate costs at the account or service level — they don't surface which individual volumes are idle, over-provisioned, or orphaned.
- Uptime-first incentives. When engineering SLAs measure availability and incident frequency — not utilization — over-provisioning is the safe call. Running out of disk space at 2am is a visible incident; allocating too much never shows up on anyone's dashboard.
Automation That Provisions But Never Cleans Up
These visibility gaps create a third problem: automation compounds the mess. CI/CD pipelines and DevOps tooling have made it trivial to spin up dev, test, and staging environments on demand. Almost none of that automation includes cleanup or decommissioning logic. Volumes created for a sprint get left running after the branch is merged. Snapshots pile up because the backup policy has no expiration rule. Over months, these become significant costs with nothing to show for them.
Key Categories of Cloud Storage Waste
Storage waste doesn't follow a single pattern. Each type accumulates differently, persists for different reasons, and requires a different remediation approach.
Unattached (Orphaned) Volumes
These are block storage volumes that were once attached to a compute instance. When the instance was terminated, the volume wasn't. AWS, Azure, and Google Cloud all continue billing for unattached volumes. AWS Trusted Advisor flags EBS volumes averaging less than 1 IOPS per day over seven days. Azure documentation explicitly notes that managed disks persist and accrue charges after VM deletion.
Over-Provisioned Volumes
Storage allocated well above actual usage requirements — often at multiples of real demand — to buffer against spikes that rarely materialize. AWS Compute Optimizer uses a 14-day lookback to identify EBS volumes where provisioned capacity, IOPS, and throughput significantly exceed actual workload patterns. This is the most common form of storage waste: it's present in nearly every environment and rarely corrected.
Orphaned Snapshots
Automated backup policies generate snapshots continuously. Without enforced retention windows or expiration rules, those snapshots accumulate indefinitely. The FinOps Foundation's Usage Optimization Library calls out aged snapshots and AMI snapshots as distinct waste categories.
Google Cloud's documentation notes that snapshotting an idle disk before deletion can reduce maintenance costs by 35% to 92%. That range suggests most organizations are paying for snapshot accumulation they've never audited.
Unmounted and Zero-I/O Volumes
Technically attached but showing no read/write activity. Common in decommissioned microservices, deprecated application components, or forgotten development environments. AWS flags volumes with fewer than 1 IOPS per day over seven days; Google identifies idle Persistent Disk volumes unattached for 15 days.
 with detection and remediation breakdown](https://file-host.link/website/lucidity-acbl2n/assets/blog-images/3d51bfe4-abca-42bc-86cf-3e99f0565454/1780395611041386_a60333526edc43dfb928f9b609486f17/360.webp)
Native cloud dashboards and standard advisor tools surface some of these issues — but not all four. Lucidity's Lumen identifies and prioritizes every category: unattached, reserved, unmounted, and zero-I/O disks that would otherwise stay invisible. For each volume, Lumen surfaces historical IOPS, throughput, latency, and cost trends, giving teams the context to act decisively instead of deferring cleanup indefinitely.
How to Minimize Cloud Storage Waste in Your Organization
Start With Volume-Level Visibility
You cannot optimize what you cannot see. Account-level cost breakdowns don't show which specific volumes are idle. The first step is establishing genuine visibility at the individual volume level across every cloud provider in your environment.
Native tools help but have limits. AWS Compute Optimizer and Trusted Advisor surface some recommendations. Azure Cost Management offers general guidance. Google's idle resource recommendations cover basic cases. None of them provide a unified, cross-cloud view with full historical context.
Lucidity's free Assessment tool connects to AWS, Azure, and Google Cloud in under five minutes — no agents, no infrastructure changes, no permissions headaches — and immediately surfaces disk utilization rates, idle volumes, and projected savings across your entire storage estate. For organizations that have never looked at storage waste systematically, the results are usually surprising.
Implement Storage Lifecycle Policies
Visibility without action just produces reports. Lasting waste reduction requires operational policies:
- Snapshot retention windows: Every backup policy should have an explicit expiration rule. Snapshots that accumulate for 18 months without a retention policy represent pure cost.
- Auto-tagging with ownership metadata: Volumes without an owner tag are the ones that persist after the person who created them leaves or moves teams. Mandatory ownership and expiration tags at creation time make cleanup tractable.
- Environment-specific review schedules: Dev and test environments are the highest-concentration source of orphaned volumes. Scheduled reviews — or better, automated decommissioning triggers — prevent accumulation.
The FinOps Foundation's optimization guidance specifically calls out tagging schemas, lifecycle policies, and block storage tier requirements as foundational practices for storage cost management.
Shift From Reactive to Autonomous Management
The root cause of persistent storage waste is that manual remediation doesn't happen at scale. Engineers know they should rightsize storage. They don't, because it's risky, time-consuming, and the providers make shrinking genuinely hard.
Autonomous management platforms address this directly: they continuously monitor every volume, identify optimization opportunities, and execute changes (expansion, shrinking, tier adjustments) without downtime or code changes.
Lucidity's AutoScaler runs this process continuously across AWS, Azure, and Google Cloud. It maintains utilization targets in real time, shrinking volumes when capacity isn't needed and expanding before workloads feel pressure.
Across Lucidity's customer base, that translates to measurable outcomes:
- Average disk utilization rises from ~30% to 75%
- Storage costs drop by up to 70%
- 100+ engineering hours reclaimed from manual provisioning and ticket triage
- Dometic cut cloud storage spend by 52% after deployment
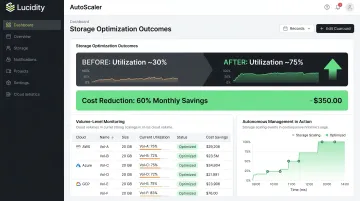
For teams still relying on quarterly reviews and manual ticket-driven cleanup, autonomous management closes the gap between what engineers intend to do and what actually gets done.
Frequently Asked Questions
What percentage of cloud spend is wasted?
Flexera's 2026 State of the Cloud Report estimates 29% of IaaS/PaaS budgets are wasted on average — up from prior years after a long decline. Storage-specific waste is often undercounted within that figure because most FinOps tools lack volume-level visibility, so idle and over-provisioned disks don't surface in standard dashboards.
What are the data storage trends in 2026?
Enterprise cloud storage spending is projected to reach $128 billion by 2028, driven by AI workloads generating training data, model checkpoints, and inference logs. Multi-cloud adoption is expanding visibility blind spots while cloud efficiency rates have declined — pushing teams toward autonomous, policy-driven storage optimization.
What are the main categories of cloud block storage waste?
The four primary categories are: unattached volumes (orphaned after instance termination), over-provisioned disks (allocated well above actual usage), orphaned snapshots (accumulated without retention policies), and zero-I/O or unmounted volumes (attached but inactive). Each requires different detection logic and remediation steps.
Why is shrinking cloud storage so difficult compared to expanding it?
All three major clouds support near-instant expansion, but none allow in-place shrinking. AWS prohibits decreasing EBS volume size outright; Azure and Google Cloud both require creating a new disk and migrating data. That migration complexity — combined with downtime risk — means most teams simply skip it.
How much can enterprises realistically save by eliminating cloud storage waste?
Organizations using autonomous storage optimization have achieved up to 70% reductions in block storage spend, with utilization improving from roughly 30% to 75%. Actual results vary — Dometic, for example, achieved 52% savings.
What is the difference between cloud compute waste and cloud storage waste?
Compute waste — idle VMs, oversized instances — is highly visible and tracked by most FinOps tools. Storage waste is more persistent: block storage volumes continue billing after compute resources are shut down, and they don't trigger the same cost alerts. That combination of persistence and invisibility makes storage waste uniquely difficult to address without dedicated volume-level monitoring.


